
The DP-LoRA silent corruption: how 5 months of broken fine-tuning hid in plain sight
How a device-placement ordering quirk between opacus, PEFT, and HuggingFace caused DP fine-tuning to silently break, and what to check in your own setup.

In late November 2025 a researcher ran a differentially private fine-tuning experiment on a sensitive language modeling task. Six runs in total: two model architectures crossed with three privacy budgets, about 45 GPU hours of compute. The training logs looked normal: loss decreasing, the privacy budget incrementing the way it’s supposed to, checkpoints saving without complaint. Every monitoring surface they had said the runs were healthy.
The trained models were unusable at inference. All six of them.
Worth pausing on the detection because it’s half-accidental. They were sweeping three values of ε expecting the usual privacy-utility tradeoff, where smaller ε means more injected noise and a noisier model. What they observed was identical utility collapse at every privacy budget, and that shouldn’t be possible. ε should make a visible difference. So they did the dumb thing, snapshotted a LoRA adapter weight from one of the trained checkpoints and compared it to its initialization. Same number, to whatever precision they cared to check.
What follows is the story of how that got tracked down. There’s a five month investigation in here, three reproduction environments, one false root cause, and a device-placement ordering quirk that turns out to be a known opacus limitation but was nowhere a user would find it. The fix is four lines of Python in a specific order. The post-mortem is also an argument for one specific sanity check in every DP fine-tuning run you ever do.
What DP-LoRA is supposed to do
If you don’t work on this every day, two paragraphs of background.
DP-SGD is the standard recipe for differentially private deep learning. Each per-sample gradient gets clipped to a fixed L2 norm, you sum across the batch, you add Gaussian noise calibrated against the sensitivity, and that’s the optimizer step. Compose across training, and you get an (ε, δ)-DP guarantee on the released model. The standard PyTorch implementation is opacus, which is maintained by Meta and the PyTorch Foundation.
LoRA (Low-Rank Adaptation, from Hu et al. 2021 freezes the base model and trains a small low rank update on top of it. For GPT-2 small that drops the trainable parameter count from 125M to around 600K, with a corresponding drop in compute, memory, and serving cost.
Combine them and you get DP fine tuning at reduced cost, with the side benefit that the injected noise lands on a smaller surface so utility at a given ε is better than with full DP fine tuning. For workflows where the training data is genuinely sensitive (medical records, financial transactions, internal corporate documents) this is increasingly the default. The integration between opacus and HuggingFace’s `peft` library is something like five lines of Python.
Those five lines turned out to be capable of silently producing a model that never updated its weights.
The bug report
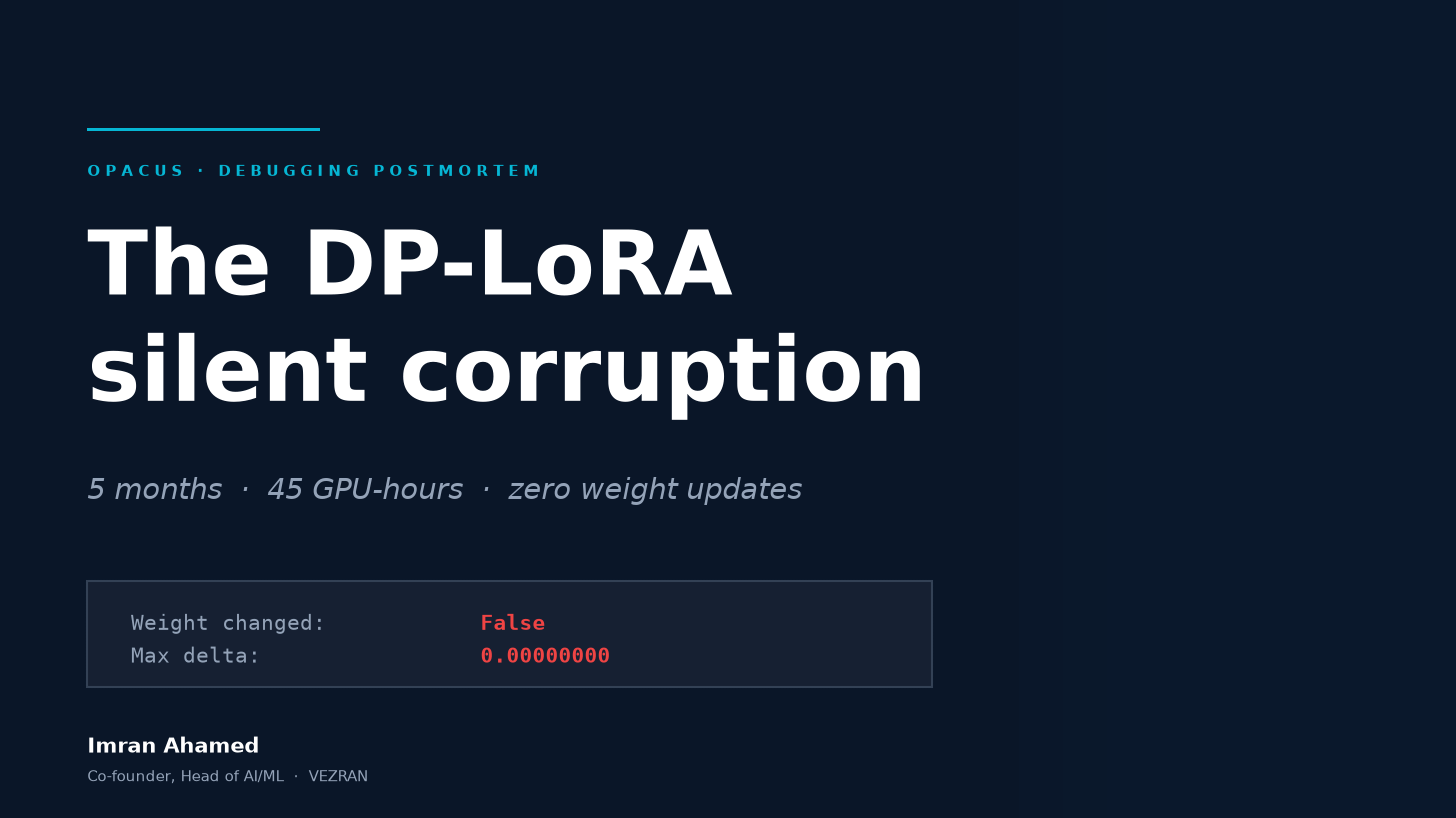
The original report came in on opacus issue #820, May 19, 2026, with a clean reproducer attached. Thirty lines of Python: load GPT-2, wrap with PEFT 0.18.1 + LoRA, hand it to opacus’s `PrivacyEngine.make_private_with_epsilon`, run one training step, check whether the LoRA weights moved.
On PEFT 0.18.1: `Weight changed: False, Max delta: 0.00000000`.
On PEFT 0.13.2 (a known older release): `Weight changed: True, Max delta: 0.00010004`.
The reporter’s hypothesis was the natural one. PEFT 0.18 had introduced changes to how LoRA parameters are organized, and they suggested that a parameter rename — something like `lora_A.weight` becoming `lora_A.dfault.weight` was breaking opacus’s hook walker. The proposed fix was to pin tutorials to the older PEFT and wait for compatibility to land.
This is a reasonable diagnosis and I want to be clear about that before I say what was wrong with it. They had a working versus broken bisect at the major release level, a plausible mechanism, a forward path. Diligent engineering. It just happened to not be what was actually going on.
Reading the source instead of trusting the timeline
When I picked up the thread the first thing I did was open the PEFT source at the two versions in question. The relevant file is `src/peft/tuners/lora/layer.py`.
At PEFT v0.13.2, line 47:
self.lora_A = nn.ModuleDict({})self.lora_B = nn.ModuleDict({})At PEFT v0.18.0, line 115:
self.lora_A = nn.ModuleDict({})self.lora_B = nn.ModuleDict({})Identical. The renamed-parameter hypothesis didn’t hold up at the source-code level. LoRA’s been a `ModuleDict[adapter_name]` for as long as 0.13.x, and the access path `lora_A.default.weight` is the same in the broken version as in the working one.
That left me with the original problem. Something else changed between 0.13.2 and 0.18.1 that broke opacus’s gradient flow, and I still didn’t know what.
The CPU bisect
The textbook next move is `git bisect` inside PEFT. But the changeset across five minor releases is huge, and I wanted to rule out the version theory entirely before I went looking for a specific commit. So I bisected at the minor-version level first.
I set up a clean Python 3.12 venv on my Mac (no CUDA, just CPU) and ran the reporter’s reproducer against every PEFT minor in the working to broken range:
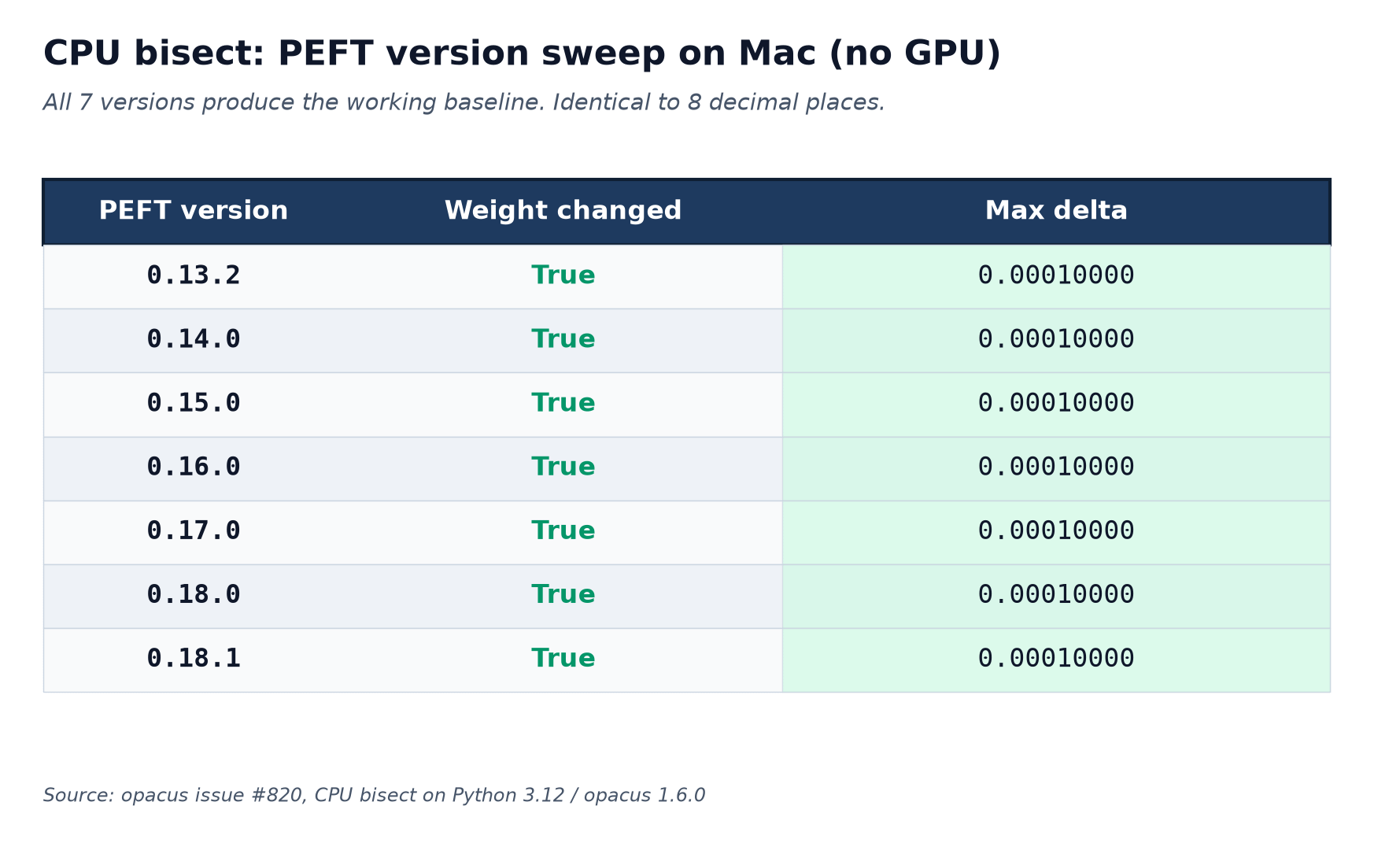
Every version produced the working baseline. Same `max_delta = 0.00010000` everywhere, identical to eight decimal places.
I sat looking at this for a while before I figured out what I was reading. The reporter had been unambiguous that 0.18.1 was broken on their setup, their reproducer was concrete, and yet on my machine every version came up clean. There wasn’t an obvious bug in their test. There wasn’t an obvious bug in my replication either. Both were correct.
The difference was CUDA. I’d been running on CPU.
The reporter’s reproducer had a line `batch = dummy.cuda() if torch.cuda.is_available() else dummy`, which moved input batches to CUDA but did nothing with the model itself. On their RTXclass GPU, the model was effectively on CUDA via lazy initialization at the first forward pass and opacus had been registered against the model before that materialization happened. On my CPU none of that was happening, the model and batches stayed on CPU, the bug evaporated.
I wrote this up in a comment on the issue with the table and the device hypothesis. The pivot in framing was: this isn’t a logic bug in PEFT or in opacus, it’s a CUDA path specific failure mode that the reporter’s reproducer wasn’t isolating.
The maintainer’s diagnostic direction
opacus is maintained by Iden Kalemaj and a small team. She read my analysis the next day and responded with a single suggestion to MN-NR: “would you mind checking if the error still appears with peft = 0.18 if you add model.cuda() before model.train()?”
The framing in her comment was generous: “following the analysis of @immu4989.” I’ll take that.
What she was asking was specific. The reporter’s reproducer never explicitly placed the model on CUDA. With newer PEFT, accelerate-style lazy device handling can defer parameter materialization until the first forward pass. If that materialization happens *after* opacus has already walked the model’s modules and registered its per-sample gradient hooks, the hooks may end up attached to parameters that no longer exist (or that exist on a different device than the rest of the model).
The fix she was asking the reporter to test was: move the model to CUDA *first*, then wrap with PEFT, then wrap with opacus. The order matters.
The GPU confirmation
A week later the reporter ran the suggested test on their RTX 5090 (CUDA 12.8, PyTorch 2.11.0).
`Weight changed: True, Max delta: 0.00010000.`
Same value as my CPU bisect. Same as the working PEFT 0.13.2 baseline. Three reproduction environments at this point converging on the same answer.
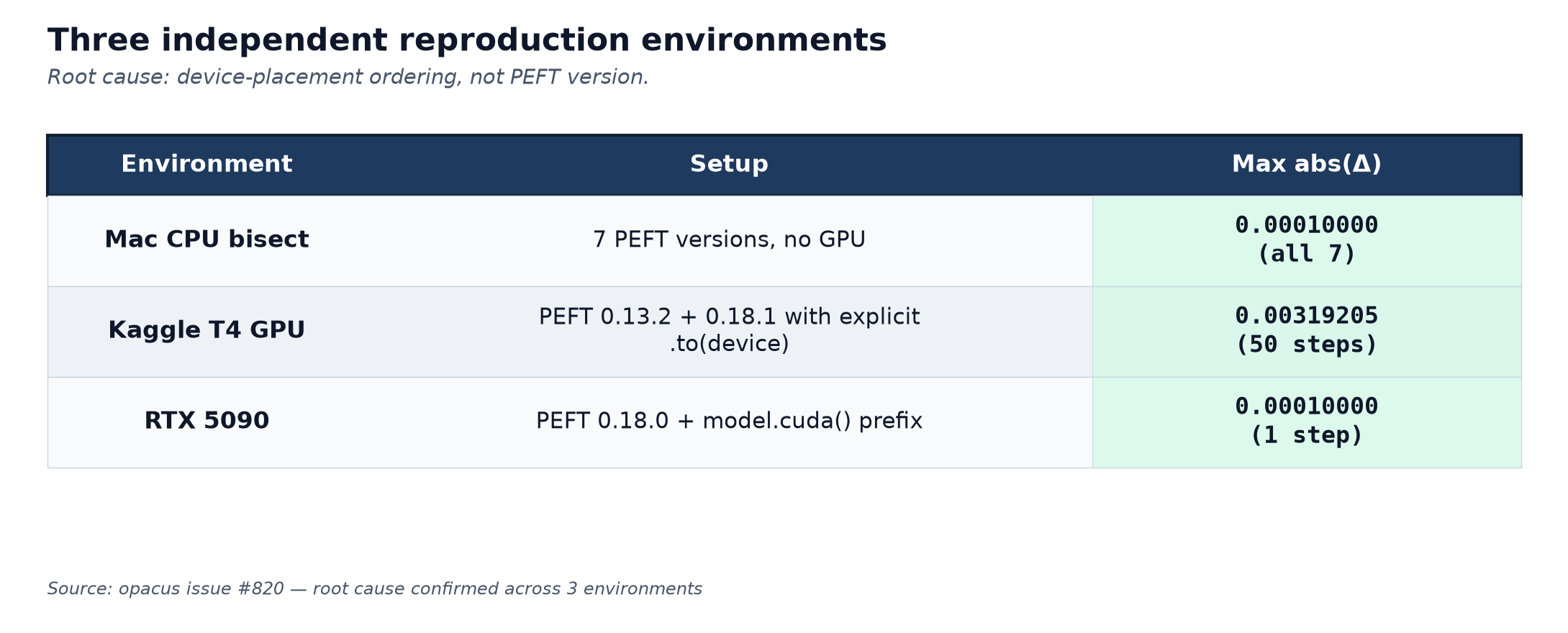
Different numbers in different rows because the runs use different step counts and learning rates, but every weight-update is in the expected magnitude bucket. The bug only ever appeared when the ordering precondition was violated.
The three safety patterns
The fix is not a code change to opacus. The library’s `make_private_with_epsilon` requires certain preconditions on the model it wraps, and those preconditions just weren’t surfaced where users were going to find them. Three patterns matter.
```python
# 1. Move base model to CUDA FIRST.
model = AutoModelForCausalLM.from_pretrained("gpt2")
model = model.to(device)
# 2. Then apply PEFT.
model = get_peft_model(model, lora_config)
# 3. Then put the model in train mode (opacus's validator requires this).
model.train()
# 4. Then wrap with opacus.
model, optimizer, loader = privacy_engine.make_private_with_epsilon(
module=model,
...,
poisson_sampling=False,
)
```Four lines, in this order. The `poisson_sampling=False` at the bottom is a separate gotcha worth flagging: GPT-2’s forward pass calls `attention_mask.view(batch_size, -1)`, which can’t handle an empty tensor, and opacus’s default Poisson sampling occasionally produces empty batches. Uniform-without-replacement sampling (what `poisson_sampling=False` activates) is a valid DP-SGD variant and avoids the edge case cleanly.
I’ve folded all of this into a new opacus tutorial for DP fine-tuning of causal language models, with the ordering rules named in prose and a working benchmark showing the utility tradeoff (about 26% relative BLEU cost at ε ≈ 7 on a small text generation task). The goal is that if you’re writing a DP+LoRA training script tomorrow you read the tutorial, you copy the pattern, you don’t hit this.
What this means for DP-ML more broadly
There’s a particular nasty quality to silent failures in differentially private machine learning that’s worth being explicit about.
A DP guarantee is a contract about how much information about training data could leak through the released model parameters. It’s enforced by the noise calibration: the Gaussian additions have enough variance that any single sample’s contribution to the trained model is statistically obscured. The accountant tracks how this composes across training steps.
In the silent corruption case all of that worked. The accountant ran, the noise was added, the privacy guarantee was technically valid. The problem was that the gradient the noise was being added to happened to be zero. The model received zero useful update plus calibrated noise, which is to say the privacy guarantee held trivially, because a model that never trained can’t leak anything about its training data. Technically private, utility-wise garbage. From a user trust perspective: you think you trained a private model and you actually trained nothing.
A few things would close this gap in opacus specifically:
1. A runtime warning when LoRA-style parameter wrappers exist alongside opacus hooks attached to non-LoRA parameters. The configuration is suspicious enough to flag.
2. A post step weight-delta sanity check baked into the `PrivacyEngine`’s example training loops.
3. Surfacing the ordering preconditions in the README and in the docstring of `make_private_with_epsilon`, in language users will see before they hit the bug.
The first is real engineering work. The second and third are documentation work the maintainers and I are now doing.
The takeaway I’d push beyond opacus specifically is that every DP fine tuning run should include a post-step “did the weights move?” check before you commit any meaningful compute. It’s about five lines of Python at the top of training: snapshot a trainable parameter, run one optimizer step, compare the snapshot to itself. Would have caught this failure mode at the cost of one iteration instead of 45 GPU-hours.
Closing
The bug was reported by MN-NR, the diagnostic direction came from Iden Kalemaj at PyTorch Foundation, and three independent reproduction environments closed it out. The tutorial PR that codifies the fix is opacus PR #830. Original thread is at #820.
If you run DP fine-tuning at all I’d recommend the tutorial once it lands, plus the four-line ordering pattern in your own training scripts, plus a weight delta sanity check at the top. opacus’s privacy guarantee is sound. The trust that it applies to a trained model rather than an untrained one is still your responsibility to verify.
Imran Ahamed is co-founder and head of AI/ML at Vezran, where the team is building Zyberpol an agentic SOC platform. He contributes to opacus, garak, PyRIT, and other open-source AI security projects.